


千人千面,这几年无论是在营销界,还是在产品运营界,都得到了很广泛的应用
千人千面,这几年无论是在营销界,还是在产品运营界,都得到了很广泛的应用。在营销行业,会用来提升营销的精准性,即做人和物的精准匹配,所谓精准营销;做产品运营的人会在产品中很多模块增加千人千面的策略,以此来达到产品流量的高效分发;在电商行业千人千面的应用尤其多,比如淘宝的猜你喜欢、京东的为你推荐,都属于此类应用。

我们先简单的聊聊到底什么是千人千面
千人千面,就其字面意思来讲就是不同的人,呈现不一样的东西。所以在所有实例中,个性化推荐是最常用的一种实践。本质上来说,个性化推荐主要的目标有两个,一个是高效连接用户和平台上的物品,让用户尽可能的发现平台上“好的东西”;另一个就是“投用户所好”,即发现用户的兴趣,基于他的兴趣为其呈现“好的东西”。
同理,上面提到“好的东西”也是个性化的。“好”与“不好”这种评判完全是基于对物品的客观评判来决定的,这种客观的评判的具体量化标准不同的业务不尽相同,但是大多都可以称之为是用户对于物品的正反馈。比如对于一件商品,可能是用户对于该商品的购买、关注、搜索、分享、好评等等。所以同一个东西,A喜欢,B可能觉得一般,甚至C可能觉得很厌烦。
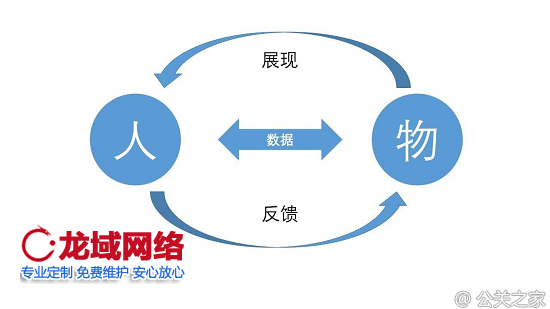
千人千面就是实现“人”和“物”高效匹配,它们之间是一个互相补充,互相依赖的关系,也就是人们看到自己感兴趣的物越多,那么对好东西的衡量也就越准确。否则就是一个恶性循环。
本质还是一个数据的交互过程。对于人来说,系统通过人们在网络的一系列行为,去判断用户感兴趣的物品,进而为他们推荐“好的东西”;对于物来说,系统通过人在为其推荐的物品上的一些列交互,比如点击、下单、购买等,来判断这个物品是不是一个“好的东西”。
简单用下面的图来表示:
2B数据增长
但是忽然有一天,我的一个公众号粉丝在后台问我,是否考虑过2B的千人千面,我心里“噔”了一下。确实,我们看了太多2C产品营销实施千人千面的案例,竟然一直没有注意到2B端。无论是从业务流程的复杂繁琐程度,还是从营销运营的现状,低效、冗余一直是2B端的产品躲不过去的伤痛。所以千人千面如果应用在2B端,那必然会是一个行业的革新。
套用一下,不妨称之为“千B千面”。
无独有偶,之前在公司做过一个2B端个性化推荐的实施,实施过程中也有过一些思考,这里分享给大家。
首先,明确一个问题,2B端的千人千面能不能做,能。但是如果想要做一个通用的架构,目前还有难度,只能做一个“局域”的。什么意思呢?比如淘宝和京东的千人千面体系,除了底层数据的差异,整个架构是可以套用的。另外,除了电商行业,对于以单个物品推荐的业务,我理解也是可以进行套用的。
再加上,目前各大企业在产品和账号体系上的互通,比如用微信,QQ,微博等一些列社交账号,可以注册各种各样的应用,导致千人千面的冷启动阶段也变得“有数可依”。
其次,如果想要在2B的产品上大规模开展千人千面的实施,会面临哪些问题。我想了想大概有下面几点:
第一、2B端的数字化程度较低。
2B端数字化、信息化,应该是近几年才提上日程,甚至是往后十年的主要方向。所以就目前来讲,B端的数据是不足以做千B千面。
举个例子,一个用户在网上点击的一个链接,购买一款商品,现在是很容易被捕捉到,并且以结构化的数据进行存储,但是一个企业与哪些供应商进行了连接,是很难被追踪记录的。
另外一方面,现在仅仅大概有30%的企业,实现了从采到销的线上化、销售化,如果大家注意观察的化,会发现很多中小企业还是一个excel去解决问题的。
第二、每一个B端是一个数据孤岛。
这就是目前整个B端的现状。可能大家会认为,这30%企业也是一个实施“千B千面”的机会啊。但是就现状而言,数据是每个企业密级最高的东西。更有企业喊出数据是公司唯一的资产,所以一个企业唯一的资产怎么会轻易的让其他人获取到?
不看别的,可以看目前云服务的现状,除了小公司出于成本的考虑愿意采用云服务,稍微大点的公司都在搞自己的云服务,没人会愿意把自己家的数据放在别人的服务器上。
所以数据对于每个企业来说,都是私有资产,神圣不可侵犯的,至少目前的认知还是在这个层面,而且从当下来看至少长期会处于这种局面。
与云面临的困境一样,在信任问题没有解决之前,B端的数据永远是一座孤岛。
第三、缺少结构化的数据。
落地过千人千面的人都清楚,结构化的数据是关键,比如做个性化推荐系统,结构化数据是用户标签,排序特征的基础保障。大多数成熟的企业数据做的都不好,更别谈小公司了。
另外,很多人对结构化的数据一直有误解。结构化的数据并不是说没有数据,而是缺少经过加工的数据,看一下关于结构化数据的定义:
结构化数据也称作是行数据,是由二维表结构来进行逻辑展示和表达的数据,严格遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
我们很容易的用结构化的数据去描述一个人,比如社会学统计信息,线上行为:基本包括:点击、浏览、加购、下单、收藏、关注、分享、订阅;线下行为:旅游、出行、饮食、居住。但是很难有一个统一的框架去描述一个B端企业,这与B端业务的多样性、复杂性、多变性密不可分。
所以如果某一天大规模的千B千面开始,那么B端结构化数据的比必定是首先迈过的槛。
第四、缺少统一的衡量标准
无论是2C还是2B千人千面的实施,都需要巨大的成本,所以必须要有一个可衡量的效果。一般来讲,2C端的千人千面主要看流量分发的效果,并且伴随业务线发展程度不同,制定指标也不尽相同。一般来讲又如下的规则:
对于新业务线,主要以流量相关的指标为核心指标,比如PV,UV这些;
对于发展中业务线,主要看流量的分发效率,所以看点击率的比较多,或者是订单转化率;
对于成熟的业务线,则主要看盈利和营收了。
但是B端呢?很难有一个统一的框架。哪怕做的是相同的行业,但是由于想法不同,那么具体的业务流程也大相径庭。比如同样是做餐饮的,做小吃和做正餐的玩法就不一样,那么每个环节衡量的指标也就不一样。一个小吃店一天买1000份小吃和一个饭店一天买1000分正菜,绝对不是一个概念。
这样会导致这么一个问题,如果把千人千面用在B端企业上,需要单独为每一个大B,小B客户进行实施,由于从业务模式,还是底层数据来看,实施难度很大,对于服务提供商来说成本投入巨大,就意味着价格很高,对于企业来说就很难接受,这就是一个恶性循环。

千B千面的一个小案例
上面讨论了在做大规模2B千人千面前需要攻克最大的难题。然后之前做过一个面向小B的个性化推荐,这个也算是一次简单的2B的千人千面,简单聊聊。
项目是为一个面向所有小B的商家提供物品采购服务的平台搭建个性化推荐系统。总体的思路和2C的千人千面类似。
数据清洗——标签挖掘——trigger机制——召回策略——排序策略——精排策略——前端展示
对于这个面向小B的推荐系统来说,主要目标就是以更小的成本让小B商家采购到想要的物品。但是同时需要考虑到供应商的供应链能力。比如海南的供应商无法给北京的商家提供采销服务。
但是,如果大家又关注线下的一些涉及到采销业务的商家,就会发现他们会有固定的合作伙伴,就是经常只会在固定的几个供应商来采购商品。
其实基于上述目标和对需求的拆解,整个思路就很明确了。最主要的还是如何建立小B和供应商之前的采销关系链。这个供应关系链会以结构化的数据进行创建,最终用于个性化推荐。
但是你会发现,这个供应关系链它是一个“局域”的。也就是当你再来一个新的2B业务,依然需要为它搭建一个新的架构,新的策略。
上面大概是之前做2B的千人千面的一个小小尝试。但是如果要做到目前2C规模的千人千面,还有很长的路要走。
